

The harvest crusher jams at 2 AM. Your night crew clears it, runs another 8 tons through, and logs "equipment issue resolved" in the maintenance book. Three weeks later, you're tasting excessive phenolic extraction across four tanks. Another month passes and you find metal shavings in the press fraction. By bottling, you've got 1,800 cases with detectable metallic notes that nobody connected back to that crusher incident — because your quality checks weren't designed to catch cascade failures.
This exact scenario played out at a 12,000-case facility in Paso Robles last vintage. They had quality checks — pH testing every 48 hours, weekly tastings, pre-bottling lab panels. What they didn't have was a winery quality assurance system that connected incidents to outcomes across the entire production timeline.
Most wineries run quality control backwards. They test at convenient points rather than critical ones. They document problems without tracking whether fixes actually worked. They sample based on schedule instead of risk. The gap between having quality checks and having an actual quality system is where good wine turns mediocre and mediocre wine becomes unsellable.
Why traditional winery QA misses the problems that actually hurt you
Walk through any mid-sized winery and you'll find clipboards hanging on tanks, binders full of lab results, and Excel sheets tracking fermentation curves. Ask how they know if their quality interventions actually worked, and you'll get blank stares.
The fundamental issue isn't testing frequency or documentation. It's that wineries treat quality as a series of independent checkpoints rather than a connected system. Your cellar team catches high VA in tank 42, adds sulfur, and moves on. Nobody tracks whether that same issue appears in adjacent tanks. Nobody documents if the intervention prevented recurrence. Nobody connects that VA spike to the faulty gasket replaced on the same tank two weeks earlier.
Quality problems in wine production rarely stay isolated. A temperature spike during cold soak affects extraction rates, which changes fermentation kinetics, which impacts malolactic completion, which influences final SO2 needs. Miss any connection in that chain and you're fighting symptoms while the root cause keeps generating new ones.
The typical approach — test when convenient, fix what's obviously broken, document the minimum for compliance — works until it doesn't. Usually that breaking point comes when you're trying to trace a quality issue across 40,000 gallons and realize your records show what happened but not why, or how problems connected to each other.
What an actual continuous QA system looks like in practice
A functioning winery quality assurance system operates on three interconnected levels that most operations never properly link together.
Streamline your winery operations effortlessly.
Corkyly helps you track, manage, and optimize every step from vine to bottle.
- Vineyard & production tracking
- Customer relationship management
- Inventory & sales analytics
No credit card required
Prevention gates stop problems before they enter your production stream. This means testing fruit at specific decision points — not just at receival but when you're deciding harvest dates, determining processing order, and allocating to specific tanks. Each gate needs clear pass/fail criteria. Brix between 23-25? Pass to standard processing. Below 23? Route to extended maceration protocol. Above 25.5? Flag for potential stuck fermentation monitoring.
Process monitoring catches deviations while you can still correct them. Sampling cadence should match risk, not convenience. Tanks with previous issues need daily testing. Standard fermentations might stretch to every 72 hours. The key is tying sampling frequency to actual risk factors — previous problems in that vessel, new yeast strains, temperature fluctuations, adjacent tank issues.
Corrective loops ensure fixes actually work and similar problems don't recur. This is where most wineries completely fail. You add nutrients to address sluggish fermentation, but do you test 12 hours later to confirm fermentation restarted? Do you flag other tanks with the same yeast lot for preventive treatment? Do you document which interventions worked for future reference?
Here's what this looks like mapped to actual production flow:
| Production Stage | Critical Gates | Sampling Trigger | Pass/Fail Criteria | Failure Protocol |
|---|---|---|---|---|
| Pre-harvest | Vineyard maturity | 2x weekly from veraison | pH 3.2-3.6, TA >5.5 | Delay pick or acid adjustment plan |
| Receival | Fruit inspection | Every bin | <2% MOG, <5% raisining | Reject or special handling |
| Crush/destem | Equipment check | Start of shift + every 4 tons | No metal particles, stems <3mm | Stop line, full inspection |
| Fermentation | Kinetic monitoring | Risk-based: 24-72 hrs | Daily drop 1-3 Brix | Nutrient protocol, temperature adjust |
| Pressing | Fraction separation | Each press cycle | Taste + pH differential | Separate lots, blend decision |
| Aging | Barrel monitoring | Monthly + problem triggers | SO2 >25ppm, VA <0.6 | Top, adjust, increased monitoring |
| Pre-bottling | Stability testing | Every blend component | Protein/cold stable, micro clean | Hold for treatment |
| Bottling | Line QC | Hourly + changeovers | Fill level ±2%, closure spec | Stop, adjust, recheck previous hour |
Notice how each gate connects to specific lot IDs? That's intentional. When you detect high VA in bottle six months later, you need to trace back through pressing fractions, fermentation vessels, and specific vineyard blocks. Without lot-level traceability tied to your QA data, you're just documenting problems without learning from them.
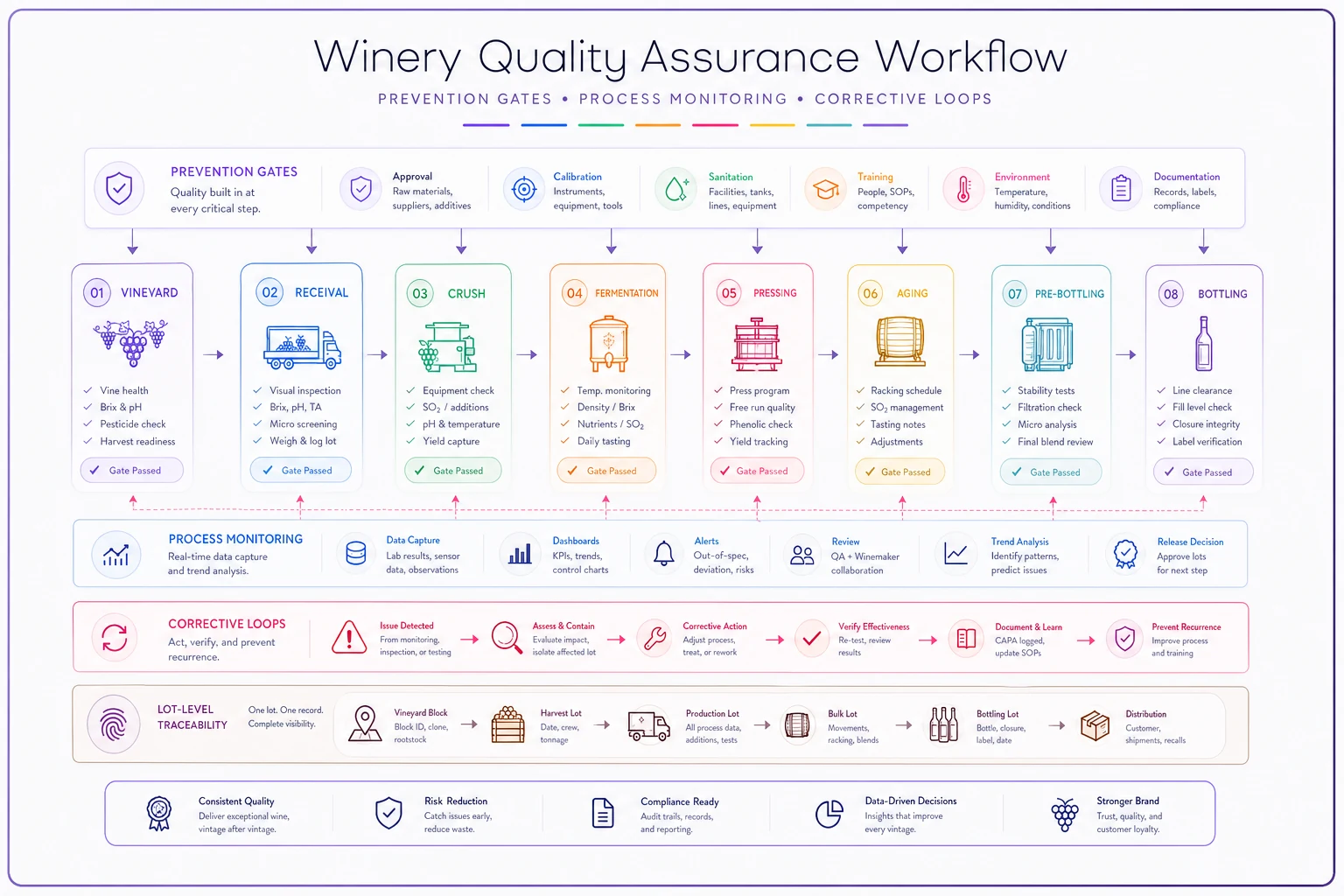
A working example: you detect elevated acetaldehyde in tank 15. Your system should instantly show all fruit lots that entered that tank, their incoming quality metrics, any incidents during fermentation, all corrections applied with verification results, any lots that received wine from this tank, and downstream quality tests on those recipient lots.
The CAPA framework nobody explains properly
CAPA — Corrective Action Preventive Action — sounds like corporate quality-speak, but for wineries it's the difference between fixing the same problem every vintage versus actually solving it. Most operations get this completely wrong by focusing on the paperwork instead of the process loops.
Real CAPA starts with immediate containment. Tank showing brett markers? Your first action isn't root cause analysis — it's preventing spread. Isolate the tank, check adjacent vessels, review any shared equipment or transfers. Document what you contained and how, tied to specific lot numbers.
-
Isolate affected lots (document all IDs)
-
Check connected equipment and vessels
-
Sample adjacent products
-
Hold any movements pending investigation
-
Assign clear ownership for resolution
Root cause investigation:
-
Timeline the problem backwards
-
Review all connected QA data points
-
Check equipment maintenance logs
-
Interview actual operators, not just managers
-
Look for similar past incidents
Verification loops:
-
Test effectiveness after 24 hours
-
Re-test after one week
-
Monitor similar risk points
-
Document what worked and what didn't
-
Update protocols based on results
One thing everyone misses: you need standard templates for different incident types. Microbial issues follow different investigation paths than chemical imbalances or equipment failures. Without templates, every incident becomes a custom investigation that takes too long and misses critical checks.
Building sampling schedules that catch problems early enough to matter
Random sampling is worse than no sampling because it gives you false confidence. The 50,000-liter tank you check weekly might be fine, while the 5,000-liter tank you haven't touched in three weeks is developing VA that will contaminate your entire blend.
Effective sampling schedules layer three different triggers.
Risk-based frequencies adjust to actual probability of problems. New barrels get monthly SO2 checks. Three-year-old barrels might need bi-weekly. Tanks with history of temperature swings need daily monitoring during fermentation. Stable vessels can stretch to 72 hours. The schedule flexes based on data, not convenience.
Event-triggered sampling responds to operational activities. Just transferred wine? Test both source and destination within 12 hours. Changed temperature? Check fermentation kinetics daily until stable. Added treatment? Verify effectiveness before returning to regular schedule. These temporarily replace normal sampling with more intensive monitoring.
Problem cascade sampling expands testing when you detect issues. Find VA in one tank? Immediately test all tanks that shared pumps, hoses, or personnel in the past 72 hours. Detect protein instability? Check all lots from the same vineyard block. One positive triggers expanded sampling until you've bounded the problem.
A 15,000-case winery in Sonoma reorganized their sampling this way and cut quality holds by roughly 60% because they caught issues during fermentation instead of at blending. Their total sample count actually dropped around 20% because they stopped redundant testing on stable lots while increasing monitoring of problem areas.
Your sampling schedule should answer three questions for every test:
-
What specific decision will this result drive?
-
What's the latest point we can detect this issue and still correct it?
-
What other lots need testing if this comes back positive?
Document why each sampling frequency was chosen so future teams can audit the risk logic.
If you can't answer all three, you're probably sampling out of habit rather than purpose.
Making corrective actions stick (and knowing when they don't)
The gap between documenting a correction and confirming it worked is where most quality systems fall apart. Your team adjusts pH, logs the addition, and moves on. Two weeks later, the wine's still flabby because the acid didn't integrate properly, but nobody reconnected those dots.
Effective correction requires closure criteria — specific, measurable endpoints that prove the fix worked. Not "pH adjusted" but "pH stable at 3.45 ±0.03 for 72 hours." Not "brett treated" but "no culturable brett at 10^2 detection level after 14 days." Without closure criteria, you're documenting activities, not confirming outcomes.
Standard work instructions for common corrections prevent freelancing that creates new problems. Your senior winemaker might know to check redox potential before making copper additions, but does your night shift? Written protocols for standard corrections — nutrient additions for stuck fermentations, SO2 adjustments for microbial issues, acid/base corrections for pH — ensure consistency across shifts and experience levels. They also document what actually works versus what people think works.
Some corrections don't work, and you need an escalation path for when they fail. First nutrient addition didn't restart fermentation? Protocol says try temperature adjustment. Still stuck after 48 hours? Reinoculation protocol. Still no progress? Escalate to the winemaker for custom intervention. Each step has clear timing, clear ownership, and clear documentation requirements.
The verification timeline matters as much as the correction itself:
-
Immediate check (2-4 hours)
Did the addition incorporate?
-
Short-term verification (24-48 hours)
Is the correction holding?
-
Medium-term confirmation (5-7 days)
Any unexpected interactions?
-
Long-term validation (30 days)
Did the fix prevent recurrence?
Skip any of these checkpoints and you'll miss corrections that seemed to work but quietly created new problems downstream.
Connecting QA data to lot traceability without drowning in spreadsheets
Your existing lot traceability system means nothing if quality data lives in separate silos. Most wineries can trace a lot from vineyard to bottle but can't pull all quality tests, corrections, and incidents for that specific lot journey.
The connection point is your lot ID structure. Every quality test, every correction, every incident report must tie to specific lot identifiers. Not "Tank 23" but "2024-PN-B7-T23" where you can parse vintage, variety, block, and vessel. When lots combine or split, your QA data needs to follow those genealogies.
A working example: you detect elevated acetaldehyde in tank 15. Your system should instantly show all fruit lots that entered that tank, their incoming quality metrics, any incidents during fermentation, all corrections applied with verification results, any lots that received wine from this tank, and downstream quality tests on those recipient lots.
Without those connections, you're investigating blind. The acetaldehyde might trace to stressed fruit from block 7, but you'd never know without linked data showing that block's pre-harvest readings, receival notes, and processing observations.
Your data governance structure determines whether this is practical or painful. Consistent naming conventions, clear data ownership, and retention rules that keep quality data accessible — not archived — make investigations possible months or years after the incident.
The practical framework:
-
Every QA record includes lot ID as a mandatory field
-
Lot genealogy tracking for all blends, splits, and combinations
-
Quality data travels with lots through all transfers
-
Incident reports link all affected lot IDs
-
Historical query tools that can pull by lot, date range, or quality parameter
This doesn't require complex software. A properly structured spreadsheet system can work. The key is designing data relationships before you need them, not trying to reconstruct connections during a quality crisis.
The pre-bottling gates that actually prevent recalls
Most wineries treat pre-bottling as a final check rather than a decision gate. You've already scheduled bottling, arranged labor, coordinated with mobile bottlers — so when tests come back marginal, you bottle anyway and hope for the best.
True pre-bottling gates operate at least 14 days before scheduled bottling, with clear go/no-go criteria and specific remediation protocols for common failures. This isn't one test — it's a series of gates that progressively confirm readiness.
The 14-day gate checks stability and cleanliness: protein stability via heat test plus bentonite trials if needed, cold stability via freezer test and tartrate check, microbiological status via plating and microscopy, SO2 molecular at target for pH, and dissolved oxygen within range.
Failures here trigger specific treatment protocols with re-testing requirements. Protein unstable? Bentonite trial determines dosage, treatment happens within 48 hours, re-test after settling. Still unstable? Escalate to alternative fining agents or consider blend adjustment.
The 7-day gate confirms treatments worked: re-test any previously failed parameters, filterability index for crossflow and sterile filter planning, final blend confirmation and analytical alignment, closure trials if using new cork lots, and label approval matches actual product.
The 48-hour gate is your final safety check — bottle trials for fill levels and closure integrity, final micro check post-filtration, SO2 adjustment confirmation, print registration and label placement, and first case quality hold for testing.
What makes this system work is escalation clarity. If wine fails the 14-day gate, you have documented paths: treat and re-test, delay bottling, or downgrade to a different label tier. Each path has owners, timelines, and economic implications calculated in advance.
A 25,000-case operation in Napa implemented this gateway approach and eliminated post-bottling holds across three consecutive vintages. They occasionally delay bottling by a week, but that's far cheaper than holding 2,000 cases in warehouse while debating whether a quality issue is real.
Building incident templates that speed resolution and prevent recurrence
When brett shows up in your barrel room at 9 PM on Friday, your cellar team shouldn't be inventing response protocols. They should be executing a pre-built incident template that captures critical information while driving immediate containment.
Effective incident templates aren't forms — they're decision trees that guide response while capturing investigation data. Each incident type needs its own template because microbial contamination follows different investigation paths than chemical imbalance or equipment failure.
Microbial incident template structure:
-
Immediate containment steps (pre-written, not fill-in)
-
Sample collection protocol (which lots, what tests, handling requirements)
-
Communication tree (who gets notified when)
-
Investigation checklist (equipment, personnel, timeline)
-
Remediation options table (if X, then Y)
-
Verification timeline (what gets tested when)
-
Prevention assessment (what enabled this)
The template forces documentation during response, not after. Your team checks boxes as they isolate affected tanks, pull samples, notify management. The timeline builds itself. When investigation happens days later, you have contemporaneous records, not reconstructed memories.
Critical sections most templates miss:
Economic impact assessment: How much wine is affected? What's the quality downgrade cost? What's the treatment expense? This drives urgency and resource allocation.
Cross-contamination mapping: Which equipment contacted affected wine? What other lots used that equipment? When was last sanitation? This bounds your problem scope.
Decision authority matrix: Who can approve treatments under $1,000? Over $5,000? Who can decide to downgrade lots? Clear authority prevents response delays.
Real template example from a brett incident:
-
Step 1
Containment (Complete within 2 hours)
-
[ ] Stop all transfers to/from affected vessels
-
[ ] Post "HOLD" tags with incident number
-
[ ] Pull 500ml samples from affected and adjacent tanks
-
[ ] Document all lot IDs on hold
-
[ ] Notify
Cellar Manager, Winemaker, QA Lead
Step 2: Investigation (Complete within 24 hours)
-
[ ] Sample all barrels/tanks in same row
-
[ ] Check SO2 levels in affected lots
-
[ ] Review cleaning logs for past 14 days
-
[ ] List all equipment used on affected lots
-
[ ] Sample any wines that shared equipment
Step 3: Remediation (Start within 48 hours)
-
If SO2 <20ppm
Adjust to 35ppm molecular
-
If multiple vessels affected
Investigate water/air systems
-
If single vessel
Consider vessel retirement
-
If caught early (<10^3 cells/ml)
DMDC treatment option
-
If advanced
Evaluate for distillation/vinegar programs
The power comes from pre-made decisions. Your team isn't debating whether to sample adjacent tanks — the template mandates it. They're not wondering who to call — the communication tree is already defined. That speed matters when contamination can spread exponentially.
Software systems that connect QA data to actual operational decisions
Most winery software treats quality data as records to store rather than insights to act on. You can pull up last year's fermentation curves, but can you instantly see which corrective actions actually worked? Can you identify which vineyard blocks consistently require the same interventions?
Operational QA software needs to connect four data streams that usually live in isolation: production events like crushing, pressing, racking, and treatments; quality tests including lab results, sensory notes, and stability checks; corrective actions documenting what was done, when, and by whom; and outcomes tracking whether fixes worked, how long they held, and any side effects.
When these connect properly, patterns emerge that change how you operate. Maybe every wine from block 12 needs nutrient supplementation at 15 Brix. Maybe barrel vendor C consistently shows higher VA development. Maybe your Tuesday shift has three times more contamination incidents, pointing to a training gap.
The operational difference shows in daily decisions. Your cellar supervisor pulls up tank 18 and immediately sees: the last three fermentations in this vessel needed cooling interventions at day 4, the previous vintage developed VA after MLF, and this tank shares pumps with tank 17 which had brett two years ago. That context changes sampling frequency, influences processing decisions, and prevents repeated problems.
AI-powered operational software takes this further by surfacing patterns that would otherwise stay buried. When platforms analyze data across vintages and interventions, they can flag risks before they manifest — tank 23 showing similar fermentation kinetics to three previous stuck fermentations generates an alert at day 3, not day 7 when it's too late to respond cleanly.
The automation layer also handles coordination that routinely falls through the cracks:
-
Sample schedules adjust automatically based on risk triggers
-
Correction protocols populate based on test results
-
Verification reminders enforce follow-up testing
-
Incident reports auto-populate with relevant historical data
-
Dashboards show real-time quality status across all lots
This isn't about replacing winemaking judgment. It's about making sure that judgment gets applied consistently and that learnings from each vintage actually get captured. When your winemaker figures out that adding nutrients at 18 Brix prevents stuck fermentations in high-sugar lots, that knowledge gets encoded in your system instead of walking out the door if they leave.
The real economics of prevention versus reaction
A 30,000-case facility in Central Coast ran the numbers after implementing connected QA systems. Their findings challenge the conventional wisdom about quality investment.
Prevention costs:
-
Additional sampling
$8,500/year in lab fees
-
Extra labor for verification
roughly 3 hours/week
-
System setup and training
40 hours initial
-
Template development
20 hours
-
Total annual cost
roughly $22,000
Reaction costs they avoided:
-
One prevented brett outbreak
$45,000 in downgrades
-
Two caught stuck fermentations
$12,000 in quality impact
-
Eliminated four post-bottling holds
$18,000 in inventory costs
-
Reduced emergency treatments
$8,000 in overtime and materials
-
Annual savings
roughly $83,000
The 4:1 return actually understates the benefit because it doesn't capture reputation protection, team stress reduction, or the consistency customers notice over time.
Prevention also scales in ways that reaction never will. As production grows, quality problems multiply if your systems don't evolve with them. A 5,000-case winery doing spot checks might catch most issues. At 50,000 cases, those same spot checks miss problems that contaminate entire programs.
Making this actually work in your operation
Building a continuous winery quality assurance system doesn't require wholesale transformation. Start with your highest-risk point — maybe fermentation management, maybe your barrel program, maybe bottling consistency.
Pick one production stage and implement:
-
Clear pass/fail gates with specific criteria
-
Risk-based sampling schedules
-
Standard correction protocols
-
Verification requirements
-
Incident templates for common problems
Run this for one vintage, document what works and what doesn't, then expand to adjacent processes. The connections between stages develop naturally as you see how upstream gates could prevent downstream problems.
The sequence matters less than the consistency. Whether you start with vineyard sampling or bottling checks, the critical element is connecting quality data to lot IDs and tracking whether interventions actually work. Each vintage builds your knowledge base — what problems occur, which corrections succeed, what preventive measures actually prevent.
Quality systems fail when they're designed in isolation from operations. Your QA framework needs to match your actual workflows, staff capabilities, and risk tolerance. A 2,000-case artisan producer needs different gates than a 200,000-case commercial operation, but both need a systematic approach to catching, correcting, and preventing quality issues.
The investment in building these systems pays back quickly in reduced crisis management and compounds over time as your operation learns from each incident rather than repeating them. More importantly, it shifts quality from reactive firefighting to proactive management — and that's where good wines become great ones consistently, not accidentally.
Ready to elevate your winery management?
Join 500+ wineries using Corkyly to increase operational efficiency, boost customer loyalty, and grow sales.


